Archive Storage
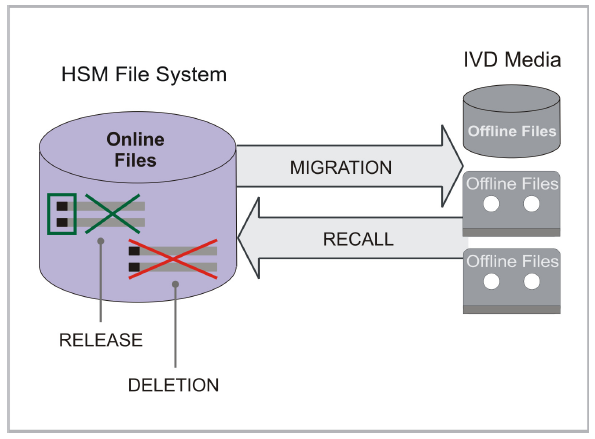
Hierarchical Storage Managment (HSM) is a data storage technique that automatically moves data between high-cost and low-cost storage media. We use a HSM system of Grau Data with the name 'grauserv'. Our archive storage on grauserv stores files that have not been accessed for a longer period of time. They are stored on a medium that is lower in the storage hierarchy, i.e. has a longer access time—in our case, magnetic tape. Slower storage media are used here because they cost less for the same storage volume. When a user attempts to access such a file, the file is first copied from the slower storage medium to the faster storage medium, a process known as recall. There are delays during this process, since the tape must first be inserted by the robotics and moved to the correct tape position. Reading from the tape is also slower than from a hard drive. This recall causes the file to change its status from offline to online. The file can now be accessed much faster until it is retrieved again.FAQs
Expand all Collapse allWhat is the purpose of the HSM archive system?


- It stores the data of the large scientific equipment like MRI/EEG/MEG/Eyetracker and so on for a sufficiently long period of at least 10 years.
- It storea completed data (that will not be changed further) like self written research papers, project data, stimuli and scripts.
Back to FAQ start
What should be considered during archiving?
- The data should be summarized before archiving because the archive system has to deal with a very, very large number of files (several tens of millions) and access to a few large files is much faster than to many small files.
- By avoiding special characters and spaces in paths and filenames, you can avoid difficult problems in the file system and simplify your life, especially when working at the command line.
Back to FAQ start
What does the directory structure look like?
The file system of the archive system is divided in two parts: '/grauserv-ro' and '/grauserv-rw'. The division into the two areas is more historical and no longer decisive.
| directory | purpose | ordered by | safekeeping period |
| /grauserv-ro/raw-data | measured data of MRI/EEG/MEG .. | device type and year | at least 10 years |
| /grauserv-ro/project | completed project data | group or department | at least 10 years |
| /grauserv-rw/scientists | self written documents (e.g. papers, thesis, stimuli, scripts) | name of the user | at least 10 years |
| /grauserv-rw/misc | miscellaneous data | year | |
| /grauserv-rw/only_5_years | short time archive | timestamp of archiving | data will be deleted after 5 years |
Back to FAQ start
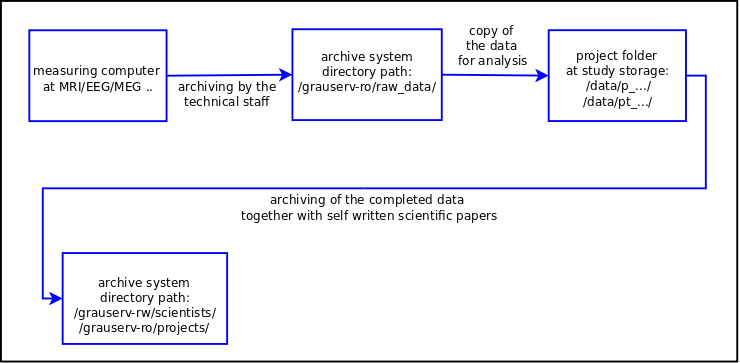
What could the data flow look like during archiving?
Back to FAQ start
How can I transfer data to the archive system or retrieve from there?
The archive system is accessible via 'secure copy', 'ssh' or 'rsync' (Windows: use WinSCP; Linux: the CLI command scp/sftp or file manager; MacOS: Cyberduck or other SFTP client). Please consider the following: All data is usually stored on tape. If you request files and directories from the archive, this data has to first be brought online. The data has to be copied from tapes (offline) to the disks (online). This takes some time depending on the amount of data and the order, in which it was stored on tapes. The IT can accelerate the access for you by bringing your directories online in preparation. Please ask IT via the Ticket system.
Back to FAQ start
What are the commands on the command line of Linux?
On the command line you can do this like:
scp -r grauserv:/grauserv-ro/raw_data/.. /data/..To archive a personal folder using rsync:
rsync -a /data/.. [LOGIN]@grauserv://grauserv-rw/scientists/[FIRST_LETTER_OF_LOGIN]/[LOGIN]/List files/folders in your archive execute the command 'ls' via ssh:
ssh [LOGIN]@grauserv ls -l /grauserv-rw/scientists/[FIRST_LETTER_OF_LOGIN]/[LOGIN]/
Back to FAQ start
Ideas, requests, problems regarding Foswiki? Send feedback